
Table Of Contents
Mistral AI has officially launched NeMo, a groundbreaking 12B model developed in collaboration with NVIDIA. This state-of-the-art model offers an unprecedented context window of up to 128,000 tokens and claims superior performance in reasoning, world knowledge, and coding accuracy for its size category.
Unmatched Performance and User-Friendly Design
The partnership between Mistral AI and NVIDIA has culminated in a model that not only excels in performance but is also designed for ease of use. Mistral NeMo aims to seamlessly replace systems currently utilizing Mistral 7B, thanks to its standard architecture.
Open-Source Availability Under Apache 2.0 License
To foster adoption and further research, Mistral AI has released both pre-trained base and instruction-tuned checkpoints under the Apache 2.0 license. This open-source strategy is expected to attract researchers and enterprises, accelerating the model’s integration into diverse applications.
Advanced Features for Efficient Deployment
A standout feature of Mistral NeMo is its quantization awareness during training, enabling FP8 inference without sacrificing performance. This capability is crucial for organizations aiming to deploy large language models efficiently.
Performance Benchmarks
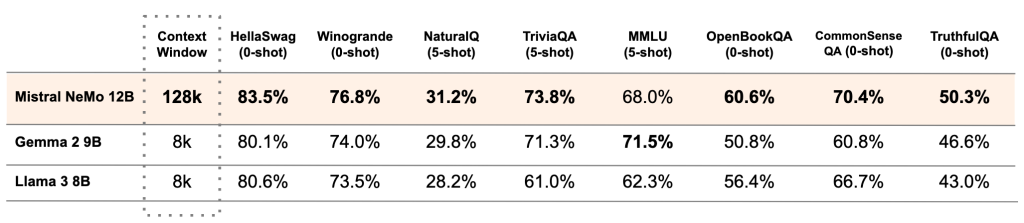
Mistral AI has provided comparative performance data between the Mistral NeMo base model and two recent open-source pre-trained models: Gemma 2 9B and Llama 3 8B. “The model is designed for global, multilingual applications. It excels in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi,” explained Mistral AI. “This marks a significant step toward bringing advanced AI models to everyone, in all languages that form human culture.”
Introducing Tekken: A New Tokenizer
Mistral NeMo also debuts Tekken, a new tokenizer based on Tiktoken. Trained on over 100 languages, Tekken offers superior compression efficiency for both natural language text and source code, outperforming the SentencePiece tokenizer used in previous Mistral models. The company reports that Tekken is approximately 30% more efficient at compressing source code and several major languages, with even greater gains for Korean and Arabic.
Availability and Integration
The model’s weights are now accessible on HuggingFace for both the base and instruct versions. Developers can start experimenting with Mistral NeMo using the mistral-inference tool and adapt it with mistral-finetune. For those on Mistral’s platform, the model is available under the name open-mistral-nemo.
In alignment with its collaboration with NVIDIA, Mistral NeMo is also packaged as an NVIDIA NIM inference microservice, available through ai.nvidia.com. This integration could simplify deployment for organizations already invested in NVIDIA’s AI ecosystem.
A Leap in AI Democratisation
The release of Mistral NeMo signifies a major advancement in the democratization of advanced AI models. By combining high performance, multilingual capabilities, and open-source availability, Mistral AI and NVIDIA are positioning this model as a versatile tool for a wide array of AI applications across various industries and research fields.